
[알고리즘] 정렬 알고리즘(Sorting Algorithm)
정렬 알고리즘
원소들을 번호순이나 사전 순서와 같이 일정한 순서대로 열거하는 알고리즘
내부정렬(Internal Sort)
입력의 크기가 주기억 장치의 공간보다 크지 않은 경우
외부정렬(External Sort)
입력의 크기가 주기억 장치 공간보다 큰 경우, 보조 기억 장치에 있는 입력을 여러 번에 나누어 사용
계산 복잡도 이론(Computational Complexity Theory)
복잡도의 기준은 알고리즘이 소모하는 소요 시간과 메모리 사용량 등의 자원이다.
전자를 시간 복잡도, 후자를 공간 복잡도라 한다.
알고리즘의 시간복잡도는
어떤 함수의 증가 양상을 다른 함수와의 비교로 표현하는 수론과 해석학의 방법인 점근 표기법 중 빅오 표기법을 사용한다.
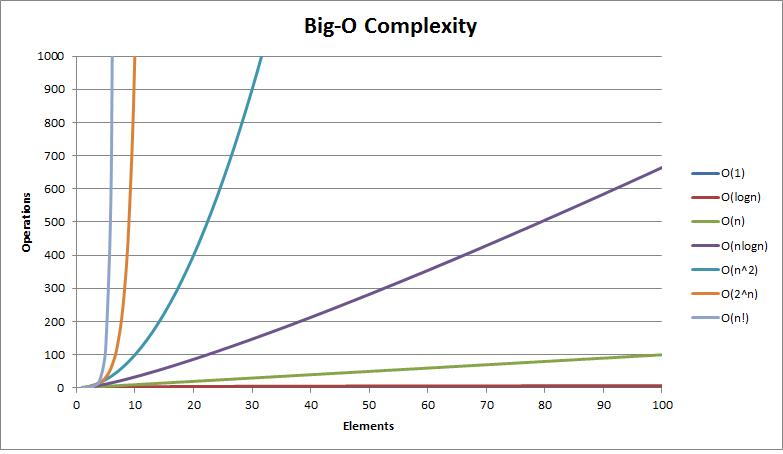
빅 오 표기법(Big-O)
수리과학의 여러 분야에서 함수의 증감 추세를 비교하는 표기법이다
알고리즘에서 시간의 복잡도를 표시하기 위하여 대문자 오(O)를 사용하여 나타내는 표기.
입력된 데이터의 크기를 n이라 가정할 때, O(n), O(2) 등으로 표기한다.
- O(1)
상수시간입력값이 아무리 커도 실행 시간이 일정한 경우 최고의 알고리즘이지만 상수값이 매우 크다면 의미가 없다. 해시 테이블의 조회 및 삽입 - O(log n)
로그시간매우 큰 입력값에도 크게는 영향을 받지 않는 경우 입력값에 영향을 받기 시작하지만 크기가 어느만큼 커져도 견고한 편이다 이진 검색 - O(n)
선형시간입력값만큼 실행 시간에 영향을 받는 경우 원하는 값을 찾기 위해 적어도 모든 입력을 살피게 되는 경우 정렬되지 않은 리스트에서 값 탐색 - O(n log n)
선형-로그시간대부분의 효율 좋은 정렬 알고리즘 병합 정렬 - O(n2)
2차시간입력값의 제곱만큼의 시간이 소요되는 경우 버블 정렬 등 비효율적인 정렬 알고리즘 - O(2n)
지수시간재귀로 계산되는 경우 - O(n!)
팩토리얼시간가장 짧은 경로를 찾는 문제 등에 브루트 포스로 풀이 무차별로 대입하는 경우로 제일 느린 알고리즘.
버블 정렬(Bubble Sort)
이웃하는 숫자를 비교하여 작은 수를 앞쪽으로 이동시키는 과정을 반복하여 정렬하는 알고리즘
오름차순으로 정렬할 때, 작은 수는 배열의 앞부분으로 이동하는데, 배열을 좌우가 아니라 상하로 그려보면 정렬하는 과정에서 작은 수가 마치거품처럼 위로 올라는 것에서 영감
거의 모든 상황에서 최악의 성능, 효율성이 낮다
의사코드
크기가 n인 배열A
for pass = 1 ~ n-1
for i = 1 ~ n-pass
if (A[i-1] > A[i])
swap A[i-1], A[i]
return A
복잡도
| 최선 시간복잡도 | O(n) |
| 평균 시간복잡도 | O(n2) |
| 최악 시간복잡도 | O(n2) |
| 공간복잡도 | O(n) |
선택정렬(Selection Sort)
입력 배열 전체에서 최솟값을 선택하여 배열의 0번 원소와 자리를 교환하고,
다음에는 0번 원소를 제외한 나머지 원소에서 최솟값을 선택하여 배열의 1번 원소와 자리를 바꾸는 과정이 정렬이 완료될 때까지 반복한다.
의사코드
크기가 n인 배열A
for i = 0 ~ n-2
min = i
for j = i+1 ~ n-1
if(A[j] < A[min])
min = j
swap A[i], A[min]
return A
복잡도
| 최선 시간복잡도 | O(n2) |
| 평균 시간복잡도 | O(n2) |
| 최악 시간복잡도 | O(n2) |
| 공간복잡도 | O(n) |
삽입정렬(Insertion Sort)
배열이 정렬된 부분과 정렬이 안 된 부분으로 나누고,
정렬이 안 된 부분의 가장 왼쪽 원소를 정렬된 부분의 적절한 위치에 삽입하고 그 뒤의 원소를 한 칸씩 뒤로 밀어내는 방식
의사코드
크기가 n인 배열A
for i=1 ~ n-1
currentElement = A[i] # 정렬이 안 된 부분의 가장 왼쪽 요소
j = i-1
while(j >= 0) && (A[j] > CurrentElement)
A[j+1] = A[j]
j = j-1
A[j+1] = CurrentElement
return A
복잡도
| 최선 시간복잡도 | O(n) |
| 평균 시간복잡도 | O(n2) |
| 최악 시간복잡도 | O(n2) |
| 공간복잡도 | O(n) |
병합정렬(Merge Sort)
입력이 2개의 부분문제로 분할되고, 부분문제의 크기가 1/2로 감소하는 분할 정복 알고리즘
즉, N개의 숫자들을 N/2개씩 2개의 부분문제로 분할하고,
각각의 부분문제를 재귀적으로 합병 정렬한 후,
2개의 정렬된 부분을 합병하여 정렬한다.
데이터 크기만한 메모리가 더 필요하지만 최대의 장점은 데이터의 상태에 별 영향을 받지 않는다는 점이다.
의사코드
MergeSort(A, p, q) # 입력 A[p]~A[q]
if(p < q>)
k = |(p+q)/2|
MergeSort(A, p, k)
MergeSort(A, k+1, q)
A[p]~A[k] / A[k+1]~A[q] 합병
복잡도
| 최선 시간복잡도 | O(nlogn) |
| 평균 시간복잡도 | O(nlogn) |
| 최악 시간복잡도 | O(nlogn) |
| 공간복잡도 | O(n) |
힙정렬(Heap Sort)
힙(Heap)
힙은
힙 조건을 만족하는 완전 이진트리이다.
힙 조건이란, 각 노드의 값이 자식 노드의 값보다 커야하는 것을 의미.
노드의 값은 우선순위라고 일컫는데 따라서 힙의 루트에는 가장 높은 우선순위(가장 큰 값)가 저장되어 있다.
힙 정렬은 최대 힙 트리나 최소 힙 트리를 구성해 정렬을 하는 방법이다.
힙의 루트에는 가장 큰 수가 저장되므로, 루트의 숫자를 힙의 가장 마지막 노드에 있는 숫자와 교환한다.
(즉, 가장 큰 수를 배열의 가장 끝으로 이동시킨 것)
루트에 새로 저장된 숫자로 인해 위배된 힙 조건을 해결하여 조건을 만족시킨다.
힙 크기를 1 줄인다. (루트를 출력하고 힙에서 제거)
이러한 과정을 반복하여 나머지 원소를 정렬한다.
추가적인 메모리를 전혀 필요로 하지 않는다는 점과, 최악의 경우 O(n2)의 성능을 내는 퀵정렬과 달리 항상 O(nlogn) 정렬의 성능을 발휘하는 장점이 있다.
의사코드
heapify(i) # 위배된 힙 조건을 만족시키기 위한 함수
l = 왼쪽노드
r = 오른쪽노드
if(l <= Heapsize && A[l]>A[i])
big = l
else
big = i
if(r <= Heapsize && A[r]>A[big])
big = r
if big != i
swap A[i], A[big]
heapify(i)
build_max_heap()
HeapSize = Length
for i = Length/2 ~ 1 (--)
heapify(i)
build_max_heap(A)
for i = length ~ 2
swap A[1], A[i]
HeapSize = HeapSize-1
heapify(A, i)
복잡도
| 최선 시간복잡도 | O(nlogn) 모든 키가 구별되는 경우 |
| 평균 시간복잡도 | O(nlogn) |
| 최악 시간복잡도 | O(nlogn) |
| 공간복잡도 | O(n) |
셀정렬(Shell’s Sort)
삽입 정렬이 거의 정렬된 배열에서 최적의 성능을 내는 것에서 착안한 정렬 방법
버블 정렬,삽입 정렬에서 이웃하는 원소의 숫자들끼리의 비교를 통해서 느리게 이동하는 단점을보완
삽입 정렬을 이용하여 배열 뒷부분의 작은 숫자를 앞부분으로 빠르게 이동시키고,
동시에 앞부분의 큰 숫자는 뒷부분으로 이동시키며, 가장 마지막에는 전체에 대해 삽입 정렬을 수행한다.
의사코드
for each gap h 큰 간격 부터 차례로
for i = h ~ n-1
CurrentElement = A[i]
j = i
while(j >= h) && (A[j-h] > CurrentElement)
A[j] = A[j-h]
j = j-h
A[j] = CurrentElement
return A
복잡도
| 최선 시간복잡도 | O(nlogn) |
| 평균 시간복잡도 | O(nlogn) |
| 최악 시간복잡도 | O(n4/3) |
| 공간복잡도 | O(n) |
퀵정렬(Quick Sort)
원소 하나를 기준(피벗)으로 삼아 그보자 작은 것은 앞으로 빼내고 그 뒤에 피벗을 옮겨 피벗보다 작은 것, 큰 것으로 나눈 뒤 나누어진 각각에서 다시 피벗을 잡고 정렬해서 각각의 크기가 0이나 1이 될 때까지 정렬.
의사코드
QuickSort(A, l, r) # 배열A, 왼쪽, 오른쪽
if(l < r)
피봇(p)을 A[l]~A[r] 중 적절한 알고리즘으로 인하여 선택
피봇을 A[l]과 교환한 후
피봇과 배열의 각 원소를 비교하여 피봇보다
작은 숫자들은 A[l] ~ A[p-1]로 옮기고
큰 숫자들은 A[p+1] ~ A[r]로 옭기고 피봇은 A[p]에 놓는다.
QuickSort(A, l, p-1)
QuickSort(A, p+1, r)
복잡도
| 최선 시간복잡도 | O(nlogn) |
| 평균 시간복잡도 | O(nlogn) |
| 최악 시간복잡도 | O(n2), 피벗을 최대값/최소값으로 설정할 경우 |
| 공간복잡도 | O(n) |
기수정렬(Radix Sort)
비교정렬이 아닌, 숫자를
부분적으로 비교하는 정렬 방법 제한적인 범위 내에 있는 숫자에 대해서 각자릿수별로 정렬하는 알고리즘.
어느 비교정렬 알고리즘보다 빠르다는 장점을 가지고 있다.
의사코드
n개의 r진수
for i = 1 ~ K(K자리 숫자)
각 숫자의 i자리 숫자에 대해 안정한 정렬을 수행
return A
복잡도
| 최선 시간복잡도 | O(n) |
| 평균 시간복잡도 | O(dn) d는 데이터의 자릿수 |
| 최악 시간복잡도 | O(dn) |
정렬 알고리즘의 속도 비교

댓글남기기